Empathic extended reality in the era of generative AI Download PDF
Poorvesh Dongre
1

,
Majid Behravan
2
,
Denis Gračanin
1,*
*Correspondence to:
Denis Graanin, Department of Computer Science, Virginia Tech, 220 Gilbert Street, Room 3207, Blacksburg, VA 24060, USA.
E-mail: gracanin@vt.edu
Empath Comput. 2025;1:202509. 10.70401/ec.2025.0009
Received: March 27, 2025Accepted: June 26, 2025Published: June 29, 2025
Abstract
Aims: Extended reality (XR) has been widely recognized for its ability to evoke empathetic responses by immersing users in virtual scenarios and promoting perspective-taking. However, to fully realize the empathic potential of XR, it is necessary to move beyond the concept of XR as a unidirectional “empathy machine.” This study proposes a bidirectional “empathy-enabled XR” framework, wherein XR systems not only elicit empathy but also demonstrate empathetic behaviors by sensing, interpreting, and adapting to users’ affective and cognitive states.
Methods: Two complementary frameworks are introduced. The first, the Empathic Large Language Model (EmLLM) framework, integrates multimodal user sensing (e.g., voice, facial expressions, physiological signals, and behavior) with large language models (LLMs) to enable bidirectional empathic communication. The second, the Matrix framework, leverages multimodal user and environmental inputs alongside multimodal LLMs to generate context-aware 3D objects within XR environments. This study presents the design and evaluation of two prototypes based on these frameworks: a physiology-driven EmLLM chatbot for stress management, and a Matrix-based mixed reality (MR) application that dynamically generates everyday 3D objects.
Results: The EmLLM-based chatbot achieved 85% accuracy in stress detection, with participants reporting strong therapeutic alliance scores. In the Matrix framework, the use of a pre-generated 3D model repository significantly reduced graphics processing unit utilization and improved system responsiveness, enabling real-time scene augmentation on resource-constrained XR devices.
Conclusion: By integrating EmLLM and Matrix, this research establishes a foundation for empathy-enabled XR systems that dynamically adapt to users’ needs, affective and cognitive states, and situational contexts through real-time 3D content generation. The findings demonstrate the potential of such systems in diverse applications, including mental health support and collaborative training, thereby opening new avenues for immersive, human-centered XR experiences.
Keywords
Extended reality, empathy, large language model, generative artificial intelligence
1. Introduction
Extended reality (XR) is an umbrella term that encompasses augmented reality (AR), virtual reality (VR), and mixed reality (MR). A key claim about XR is its ability to elicit empathetic responses through digital simulations. Empathy is defined as the capacity to understand and share the feelings of others, which is essential for meaningful social interactions. There are different types of empathy, including emotional, cognitive, and compassionate. Emotional empathy involves sharing and feeling another person’s emotions; cognitive empathy refers to understanding another person’s perspective; and compassionate empathy combines both feeling and understanding with a motivation to help.
XR and empathy can be examined from two perspectives. First, XR can be seen as an “empathy machine” that evokes emotional, cognitive, or compassionate empathy in users. From this perspective, XR experiences are designed to help users adopt another person’s viewpoint. By immersing and embodying users in realistic scenarios, XR can elicit various types of empathy toward real individuals[1] or simulated characters[2]. Second, XR can be regarded as an “empathetic entity” that responds empathetically to users by tailoring the XR experience. Such systems are designed to detect, interpret, and respond to users’ emotional and cognitive states as well as their surrounding environments. This may involve monitoring physiological signals, voice, facial expressions, and environmental context to customize the XR experience, thereby positively influencing users’ goals, mood, and comfort. Empathy-enabled XR integrates these two perspectives, establishing a bidirectional empathy link between users and XR[3,4]. This synergy transforms XR into a powerful medium for personal growth, social development, and interactive storytelling.
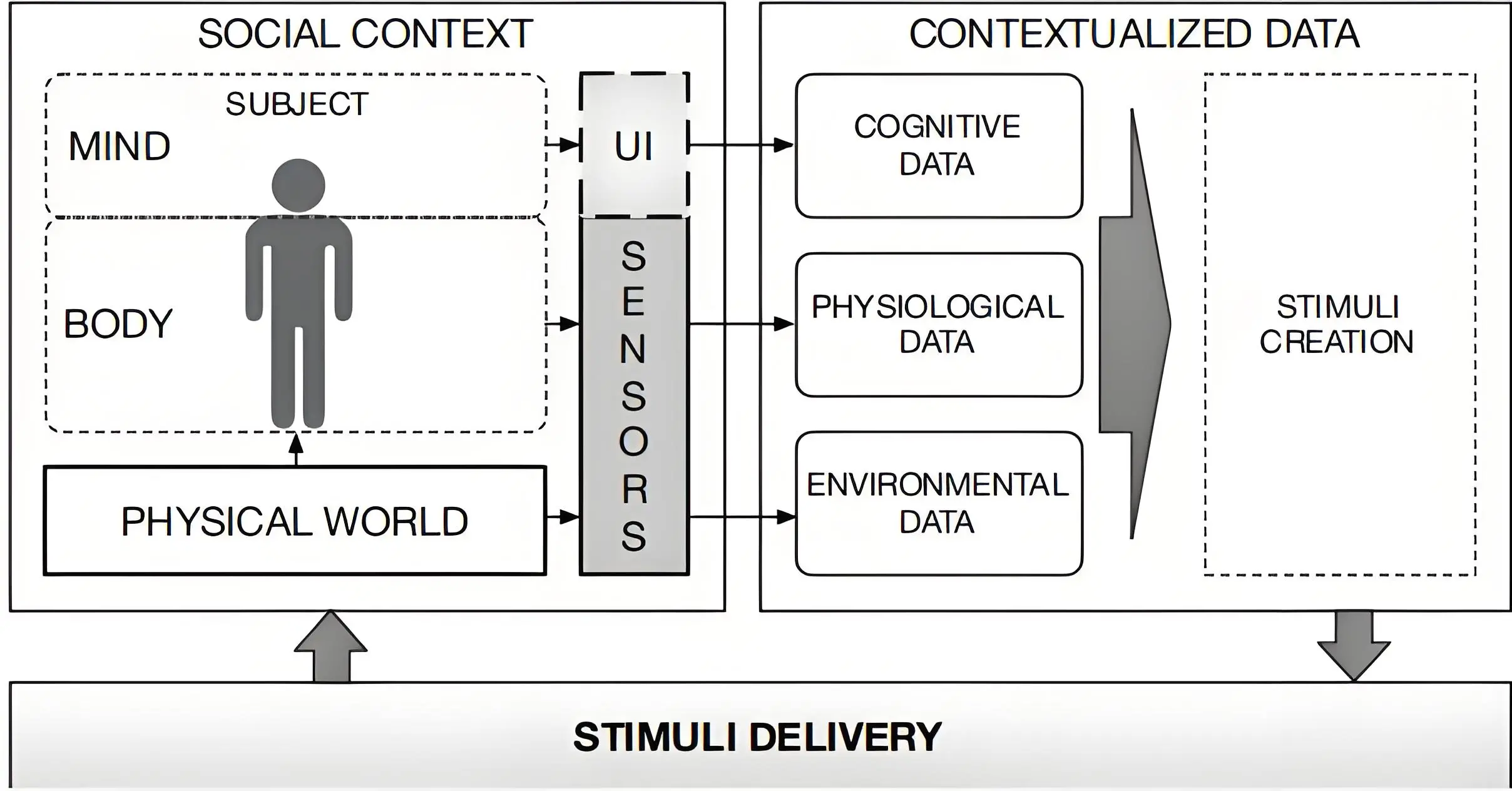
The availability of portable and affordable multimodal sensing technologies enables real-time monitoring of users and their environment during XR experiences. A physical space equipped with such sensing technologies can capture a wide range of measurements related to the user and their surroundings. These measurements, including voice, facial expressions, heart rate (HR), electrodermal activity (EDA), electroencephalogram, eye tracking and others, can be utilized to infer users’ cognitive and emotional states. This information serves both to assess the impact of XR content on users and to personalize the experience accordingly. User and environmental data can be integrated with additional measures such as self-reports to generate contextualized information about the user. Such contextualized data can further guide the customization of XR content tailored to the user (Figure 1).
Artificial intelligence (AI) is driving transformative changes in the rapidly evolving digital landscape, including emerging fields such as XR. To better explore and understand the integration of XR and AI, Wienrich and Latoschik[5] introduced the concept of the XR-AI continuum. This continuum represents a spectrum where XR and AI intersect, with two endpoints defined by the primary goal of a given XR-AI system. At one end (XR for AI), XR is employed to study the effects of potential AI embodiments on users, opening new avenues for human-AI interaction research. At the other end (AI for XR), AI serves as an enabling technology for XR applications, such as intelligent virtual environments and virtual humans. The notion of “AI for XR” creates new possibilities for developing empathy-enabled XR, where AI-driven recognition of user affect and cognition, environmental awareness, and content customization combine to deliver empathetic XR experiences.
Traditionally, AI techniques such as machine learning (ML) and deep learning (DL) have played a central role in affect and cognition recognition, serving as foundational components for empathy-enabled XR. These methods enable systems to detect users’ psychological states through physiological signals, voice, facial expressions, and behavioral cues. ML and DL also facilitate context recognition from the user’s surrounding environment. However, the recent emergence of generative artificial intelligence (GenAI), largely driven by advancements in large language models (LLMs), has introduced new possibilities in content customization, including the generation of novel XR content. LLMs have demonstrated proficiency in interpreting and generating content across diverse domains, such as education[6] and mental health[7,8]. While traditional models primarily focused on interpreting user states, LLMs can now dynamically interpret and shape narrative content, dialogue, and interaction styles based on users’ states and context, thereby opening new avenues for empathy-enabled XR experiences.
LLMs have also significantly expanded their impact on multimodal content generation, extending beyond text processing to areas such as text-to-image, text-to-video and speech-to-text synthesis[9]. These advancements enable XR systems to create emotionally and cognitively appropriate, context-aware virtual environments, avatars and narratives. Such generative capabilities enhance empathy-enabled XR by allowing systems to produce multimodal content including text, voice, images, videos and 3D objects. This shift moves user-aware systems from static designs toward dynamic, co-creative experiences where affect and cognition recognition, environmental awareness and content generation are closely integrated.
This paper presents two frameworks and their prototypes that contribute to the development of an LLM-powered empathy-enabled XR. The first framework, Empathic Large Language Model (EmLLM), is demonstrated through a physiology-driven EmLLM chatbot designed for stress management. The second framework is an LLM-powered matrix for content generation in MR, with its prototype being a context-aware MR application that generates everyday 3D objects in virtual spaces in real time. We discuss the design and evaluation of these prototypes. Finally, we integrate the EmLLM and matrix frameworks to propose a unified framework that supports the development of empathy-enabled XR experiences.
2. Background
In this section, we provide an overview of the key concepts underlying our work, including the relationship between XR and empathy as well as the integration of AI into XR systems. We begin by exploring how XR can function both as a medium to foster empathy and as a system capable of exhibiting empathic behavior. We then discuss how AI techniques, particularly ML, DL, and LLMs, support affect and cognition recognition, environmental awareness and content customization in XR.
2.1 XR and empathy
As previously discussed, XR and empathy can be examined from two perspectives. First, XR can be seen as an “empathy machine” that evokes emotional, cognitive or compassionate empathy in users. Second, XR can be considered an “empathetic entity” that responds to users’ emotional and cognitive states by customizing the XR experience accordingly. In this section, we review existing work related to both perspectives.
2.1.1 XR as empathy machine
The concept of XR as an “empathy machine” suggests that XR technologies can allow users to experience the emotions, thoughts and perspectives of others. Numerous studies have investigated this approach, highlighting XR’s potential to enhance empathy through innovative applications. This approach can be further categorized into two types: (1) standalone XR experiences that foster empathy through immersive embodiment, and (2) collaborative XR systems where physiological or attentional cues are shared among participants to support collective perspective-taking and teamwork.
In standalone XR empathy experiences, users typically engage in a single-user environment designed to replicate another individual’s experiences. When users are placed in a virtual body that differs from their own in aspects such as age, race, or physical ability, they may internalize elements of that identity, leading to shifts in self-perception and attitudes, and thereby fostering empathy. The core mechanism in this approach is embodiment and immersion. Several studies have shown that embodiment can reduce biases and promote prosocial attitudes. For example, Herrera et al.[10] conducted a large-scale study in which participants embodied an avatar representing an older adult within a virtual environment. After virtually experiencing the physical and sensory limitations associated with aging, participants reported significantly greater empathy and more positive attitudes toward older adults. In addition, high-fidelity visual, auditory, and haptic feedback can intensify immersion, thereby enhancing users’ empathic responses to virtual scenarios. For instance, Tong et al.[11] developed a VR game simulating the daily experiences of a chronic pain patient. The game used visual cues such as red pulsating overlays to indicate pain flare-ups, auditory effects including sharp winces and ambient discomfort sounds, and haptic feedback delivered through controller vibrations to simulate physical resistance and joint pain.
In collaborative XR systems, empathy is fostered through the real-time sharing of nonverbal and attentional communication cues, enabling users to perceive and respond to each other’s emotions, focus, and intentions. Nonverbal communication cues include physiological signals such as HR, EDA, and respiratory rate, which reflect affective states such as stress, calmness, or arousal. Manuel et al.[12] investigated how embodied interactions within XR environments can enhance user engagement and the overall experience of remote meetings. Dey et al.[13] examined the effects of sharing manipulated HR feedback in a collaborative VR setting and found that this feedback influenced participants’ perception of their collaborator’s emotions, thereby facilitating empathic communication. Attentional cues, such as eye gaze, head orientation, and gesture direction, help convey user focus and intent. Masai et al.[14] introduced Empathy Glasses, an XR system that integrates facial expressions, eye tracking, and head-worn cameras to support empathic communication between remote collaborators. Bai et al.[15] conducted a user study on a MR remote collaboration system that enables users to share gaze and gesture cues. They found that this system significantly enhanced the sense of co-presence, which in turn facilitated empathic communication. Jing et al.[16] further demonstrated the positive impact of shared gaze visualization in collaborative MR environments, showing that bi-directional gaze cues improved mutual understanding and emotional alignment during co-located collaboration.
2.1.2 XR as empathic entity
While much of the existing research presents XR as an “empathy machine,” a relatively less explored area is the design of XR systems that demonstrate empathic behavior. A key enabler of XR as an empathic entity is the integration of affective computing, which allows XR systems to recognize users’ emotional and cognitive states through physiological signals, voice, facial expressions, and behavioral cues. Once these states are identified, the XR system must adapt to reflect an empathic understanding of the user. This adaptation may include modifying the content, pacing, difficulty level, agent behavior, or environmental conditions within the XR experience to better align with the user’s current state. For example, Adiani et al.[17] proposed a desktop VR system featuring a virtual interviewer that adjusts its dialogue and pacing based on the user’s stress level to improve social readiness and reduce anxiety. Reidy et al.[18] developed an immersive VR training system that adapts task complexity and pacing according to valence and arousal levels in order to maintain user motivation and cognitive performance. Téllez et al.[19] designed an immersive VR football training game that modifies visual and auditory elements of the environment based on the user’s stress levels to sustain optimal engagement. These examples illustrate how XR systems can operate as empathic entities by dynamically adapting the virtual environment in response to users’ affective and cognitive states, with promising applications in training, therapy, and entertainment.
2.2 XR and AI
Integrating AI into XR systems, particularly within the “AI for XR” concept of the XR-AI continuum discussed earlier, enables a shift from passive environments to intelligent systems that can perceive, interpret, and respond to users in real time. This synergy between XR and AI serves two key functions in empathy-enabled XR systems. First, it facilitates the recognition of users’ affective and cognitive states through multimodal sensing. Second, it enables the dynamic customization of content to align with or support the user’s current state and environment. This ability to recognize and respond effectively allows XR to function both as an empathy machine and as an empathic entity. In this section, we examine both roles, focusing first on traditional predictive AI methods for recognizing user states, and then on emerging GenAI techniques for generating or customizing XR content.
2.2.1 AI for inference
AI for inference refers to computational methods used to recognize users’ affective and cognitive states based on multimodal sensing, including physiological signals, facial expressions, body posture, speech, and behavioral patterns. It also involves identifying contextual factors such as indoor temperature[20], lighting conditions[21], and the surrounding environment[22-24], which can influence or reflect a user’s emotional and cognitive state. These inference mechanisms form the foundation of empathy-enabled XR systems by enabling experiences that are emotionally and cognitively responsive.
Traditional ML algorithms such as support vector machines (SVM), random forests (RF), k-nearest neighbors, and linear discriminant analysis (LDA) are widely used in XR settings to classify affective and cognitive states. For example, Reidy et al.[18] employed SVM and LDA to classify user emotions based on facial electromyogram (EMG) signals into four quadrants of the valence-arousal model in an immersive VR game designed for memory training and enhancement. Similarly, Orozco-Mora et al.[25] used SVM and RF classifiers to recognize user stress levels from EDA, EMG, and electrocardiogram (ECG) signals in an immersive VR zombie survival game.
In recent studies, DL techniques such as one-dimensional convolutional neural networks have been used to capture complex patterns in physiological data. Petrescu et al.[26] employed convolutional neural networks (CNNs) to classify fear and arousal states, achieving high inference accuracy in immersive XR environments. These AI models are typically trained offline using labeled physiological data and then deployed in real time to detect affective changes and trigger appropriate customizations during the XR experience. Ongoing advancements in multimodal fusion techniques have further improved the robustness of user state inference in XR systems, enhancing their ability to manage noisy data and adapt to real-world variability in user emotion and cognition. Recent research has begun incorporating advanced architectures, including foundation models for learning time-series representations[27], diffusion models for generating and interpreting emotional dynamics[28], and LLMs for context-sensitive affect recognition and reasoning[29].
Accurate object detection in the surrounding environment plays a crucial role in empathy-enabled XR by tailoring immersive experiences to users’ needs. Identifying relevant objects within the user’s environment helps ground the virtual experience and can enhance the system’s perceived empathy. Recent advances in LLMs have improved these capabilities by integrating named entity recognition (NER) directly into LLM architectures. For example, Yan et al.[30] introduced LTNER, a framework that leverages GPT-3.5 to significantly improve NER accuracy through a novel Contextualized Entity Marking method. Similarly, PromptNER[31] employs prompt-based heuristics to address few-shot NER tasks, reducing training overhead while maintaining adaptability across diverse applications. These innovations contribute to more personalized and context-aware AI responses, enabling XR systems to better interpret and respond to nuanced user needs.
2.2.2 AI for customization
Once users’ states are inferred, AI plays a crucial role in customizing the XR environment to demonstrate empathic responsiveness. This customization can take various forms, ranging from rule-based approaches that apply predefined thresholds, to ML and DL models that enable dynamic adjustments, and further to GenAI techniques that create new content for XR.
Traditionally, XR customization has relied on rule-based methods. For example, Téllez et al.[19] employed a rule-based adaptation strategy that monitors stress levels and adjusts the VR football training environment to reduce user overload and maintain focus. In contrast, ML and DL approaches offer greater personalization, as these models can be trained on individual user data. Adiani et al.[17] utilized ML to detect the user’s stress state and adapt the virtual interviewer’s pacing and dialogue complexity accordingly. Similarly, Orozco-Mora et al.[25] applied ML models for real-time stress detection to dynamically modify the difficulty of a zombie survival game by increasing enemy count or speed, thereby maintaining engagement while preventing cognitive overload.
Recent developments in GenAI, particularly LLMs, have opened new opportunities for empathy-enabled XR by enabling dynamic, context-aware content generation. These advances support adaptive dialogue, personalized narratives, and emotionally resonant interactions within immersive environments. However, existing frameworks tend to focus either narrowly on LLM-driven reasoning (such as Chain of Empathy[32]) or on isolated aspects of XR asset creation (such as Dream Mesh[33]), without providing integrated pipelines for real-time, affect-aware, and environmentally contextualized XR adaptation. Our study addresses this gap by operationalizing LLMs within a unified framework that combines personalized multimodal recognition and content generation. Three key areas that significantly enhance interactive XR content generation with LLMs include speech-to-text and text-to-speech technologies, object recommendation, and text-to-3D conversion.
Gen AI for Speech-to-Text and Text-to-Speech: Speech-based input is vital for empathy-enabled XR, providing a direct channel to detect user intentions and emotional cues in real time. Recent advances in LLM-based speech processing have greatly improved automatic speech recognition (ASR), multilingual support, speech-to-text (STT), and text-to-speech (TTS) capabilities, enhancing XR systems’ ability to respond to diverse linguistic and emotional contexts. For example, integrating pre-trained speech and language models improves ASR performance without requiring extensive task-specific data[34]. SeamlessM4T unifies STT and TTS across more than 100 languages, increasing accessibility[35], and has been applied in a wide range of projects[36]. GenTranslate enhances multilingual translation quality by aggregating multiple translation hypotheses[37]. WavLLM uses dual encoders and a staged curriculum to tackle complex auditory tasks[38], while MONA’s cross-modal alignment techniques enable silent speech recognition, highlighting potential for non-invasive empathic dialogue[39]. Beyond core speech processing, incorporating acoustic markers into LLMs supports detection of mental health conditions such as depression[40], demonstrating how speech-driven models can serve as a powerful foundation for empathetic XR experiences.
LLMs for Object Recommendation: In empathy-enabled XR, context-aware recommendations play a crucial role in shaping how supportive the virtual environment is for each user. Kim et al.[41] proposed A-LLMRec, which combines collaborative filtering knowledge with LLMs to provide accurate, real-time recommendations even in data-scarce scenarios. Similarly, Cao et al.[42] addressed the gap between traditional recommender systems and LLMs by integrating user preference data directly into the language models. Together, these approaches pave the way for more personalized and empathetic XR environments, enabling systems to deliver real-time, customized recommendations that anticipate user needs based on linguistic context and behavior.
Gen AI for Text-to-3D: Recent advances in generative AI, including contrastive language-image pre-training and diffusion models, have significantly improved text-to-3D generation, which is particularly powerful for empathy-enabled XR. By allowing users to create or modify 3D objects dynamically from simple textual descriptions, XR systems can deliver more immersive, responsive, and personalized experiences. Techniques such as AutoSDF[43] and ShapeCrafter[44] utilize recursive algorithms and shape priors for innovative 3D generation. Voxelized diffusion methods like SDFusion[45] and Diffusion-SDF[46] excel at reconstructing complex shapes based on textual inputs. Other frameworks, including Michelangelo[47] and Shap-E[48], align shape, image, and text representations to produce contextually accurate and detailed 3D assets. Advanced structure-aware models like ShapeScaffolder[49] and SALAD[50] further enhance realism and functional design, making text-to-3D outputs more suitable for real-world XR interactions. These generative techniques demonstrate how LLMs empower empathy-enabled XR to rapidly customize environments in response to users’ affective and cognitive states or situational cues.
3. Problem
As discussed, empathy-enabled XR establishes a two-way empathy link between users and XR by combining XR as an “empathy machine” with XR as an “empathetic entity.” This link depends on accurately capturing the user’s affective and cognitive state as well as their surrounding environment (Figure 1). Multimodal sensing, including physiological signals, voice, facial expressions and behavioral patterns, can infer the user’s affective and cognitive states. Various multimodal sensing devices also enable inference of the user’s environment. Another important factor influencing the two-way empathy link is user immersion and embodiment in XR along with customization of the XR environment. Therefore, new methods and practical guidelines are needed to develop empathy-enabled XR environments[51]. It is also essential to build supporting infrastructure to investigate the effects of these environments on users. This infrastructure should include a testbed for developing and deploying frameworks and applications to enable data collection, fusion, inference, customization and evaluation. Based on this context, the two main research questions for LLM-powered empathy-enabled XR systems are:
RQ1: How can we accurately infer user mental states and context in XR?
This question investigates the effectiveness of combining multimodal sensing and AI-based inference techniques to recognize a user’s affective and cognitive states in real time. Additionally, it examines how such inferences can be deployed efficiently in XR environments, where latency, accuracy, and robustness to variability are critical.
RQ2: How can XR content be customized based on user state and context?
This question focuses on designing adaptive XR environments that respond empathically to users’ inferred mental states and situational context to facilitate empathy (empathy machine) and/or support the user (empathic entity). It explores how advanced AI techniques can be utilized to create or modify XR stimuli (e.g., visual assets, auditory cues, virtual agents) in real-time. The question also considers the challenge of grounding content customization in accurate user inference and personalization.
4. Proposed Approach
We address the research questions through two frameworks and their prototypes. The first framework, which targets RQ1, is called EmLLM. Its prototype is a physiology-driven EmLLM chatbot that interprets users’ mental stress from physiological signals and delivers context-aware supportive text responses for stress management. The second framework, addressing RQ2, is called the Matrix. Its prototype is a dynamic, context-aware MR application powered by multimodal LLMs. This application analyzes the user’s surrounding environment to recommend and generate interactive everyday 3D objects within the MR environment. The methodology follows four investigation phases: (1) framework design, (2) prototype implementation, (3) prototype evaluation, and (4) quantitative and qualitative analysis. The two frameworks and their prototypes are described in detail below.
4.1 Framework 1: EmLLM
EmLLM is a novel framework that integrates passive user data with predictive and generative AI to enable empathic human AI interaction[7]. Predictive AI infers users’ mental states using passive data collected from devices such as smartphones, smartwatches, and XR headsets, including modalities like physiological signals, voice, facial expressions, and behavioral cues. Generative AI, specifically LLMs, generates supportive content such as text, audio, and video to assist users based on their inferred mental state. Therefore, the two core components of EmLLM are user psychological state inference and dynamic adaptation of the LLM.
4.1.1 Psychological state inference
Human physiology and psychology are closely intertwined and exert a profound influence on each other. The process of estimating psychological states from physiological signals is known as psycho-physiological inference[52]. To achieve this, researchers typically extract features from raw physiological signals across multiple domains, including time, frequency, and statistical measures[53-56]. These features serve as inputs for rule-based methods or machine learning algorithms to infer users’ psychological states[53,57].
Voice, facial expressions, body language, and other behavioral cues can also reveal the user’s psychological state. For example, vocal features such as pitch, intensity, and energy are effective in recognizing valence and arousal[58]. Facial expressions and micro-expressions provide visible signs of spontaneous emotions and are widely utilized in emotion recognition systems[59,60]. Additionally, body posture and gestures can indicate attentiveness, engagement, or psychological discomfort, particularly in immersive XR environments where full-body tracking is often available[61,62].
DL networks offer the advantage of integrating feature extraction directly into the learning process, reducing the reliance on manually engineered features[63]. CNNs, in particular, can autonomously identify meaningful temporal features from raw physiological data and pass them to a fully connected multilayer perceptron for classification[64]. Furthermore, CNNs can be combined with recurrent architectures such as long short-term memory networks to create hybrid models that effectively handle time-series data[65,66].
These models can be further extended to perform multimodal fusion, where data from different channels such as voice, facial expressions and physiological signals are combined either at the feature level or decision level to improve inference accuracy[67]. Additional advantages of deep learning networks include their ability to process multimodal physiological data[68] and their capacity for multitask learning, which allows simultaneous prediction of related psychological states within a single model[69]. Recent studies have begun leveraging advanced architectures such as foundation models for time series representation learning[70], diffusion models for generative understanding of emotion dynamics[28], and even LLMs for psychological state inference[29].
4.1.2 Dynamic LLM adaptation
Dynamic LLM adaptation involves tailoring the model’s behavior in real time based on user context using techniques such as prompt engineering, fine-tuning, instruction tuning, retrieval-augmented generation (RAG), and multimodal conditioning. Prompt engineering includes methods like zero-shot, few-shot, chain-of-thought, and persona-based prompting[71]. In empathy-enabled systems, psychological state inferences can be encoded into dynamic prompts to guide the LLM in responding empathetically, following conversational frameworks, or reasoning through user experiences using the chain-of-empathy approach[72].
Fine-tuning a pretrained LLM on specialized datasets further refines its behavior for specific applications such as therapeutic dialogue, emotional support, or health coaching[73]. However, this process is more resource-intensive and less suitable for real-time adaptation. Instruction tuning provides a middle ground by fine-tuning the LLM on task-oriented instruction-response pairs, enabling the model to generalize to new tasks while following empathy-focused directives.
RAG supports dynamic adaptation by integrating external knowledge or memory modules during inference, enabling context-aware and consistent conversations across sessions. Meanwhile, multimodal conditioning incorporates non-textual signals such as physiological data, images, and speech[74], facilitating richer contextual understanding. This approach allows the LLM to recognize psychological states from multimodal data and deliver more personalized and empathic responses.
In the EmLLM framework, predicted psychological states can be dynamically embedded into prompts or used to condition the model’s generation behavior through auxiliary embeddings or control tokens. This enables real-time empathy by aligning the LLM’s responses with the user’s current affective or cognitive state, resulting in more empathetic interactions.
4.2 Framework 2: matrix for XR content generation
Matrix is an LLM-powered framework designed for real-time content generation in XR environments[75-77]. It processes speech inputs, generates 3D objects, and provides context-aware recommendations for 3D object creation. A key feature of Matrix is its optimization of 3D meshes, which results in smaller file sizes and faster rendering on resource-constrained XR devices. This approach addresses challenges such as high graphics processing unit (GPU) usage, large output sizes, and the need for real-time responsiveness. Additionally, a pre-generated object repository further reduces processing demands.
This framework can be applied across various domains such as education, design, and accessibility. Matrix translates verbal commands into real-time 3D visual outputs by leveraging state-of-the-art LLMs and speech-processing tools. As an open-source framework, it encourages continuous innovation across diverse industries and creates opportunities to facilitate empathic interactions within the XR environment.
Matrix primarily uses prompt engineering to dynamically interpret user commands. Through carefully designed prompts, it identifies objects and their attributes from transcribed or translated text, then suggests related objects based on the context. In addition to textual inputs, Matrix incorporates multimodal conditioning using vision-language models (VLMs). Users can capture images within an XR environment, which the system processes to detect relevant environmental details. The LLM then integrates this visual information to recommend new objects, creating a richer and more adaptive XR experience.
Although Matrix leverages a VLM for image-based scene analysis, it does not rely on full-scale fine-tuning or instruction tuning. Instead, it uses carefully designed prompt templates to guide the VLM’s behavior. Additionally, Matrix accesses a pre-generated 3D object repository to enable efficient object generation. While this pipeline resembles RAG, it functions more like on-demand resource lookups rather than a fully integrated RAG architecture.
5. Findings
Below, we present the design and evaluation of prototypes illustrating the two frameworks. The first example, the physiology-driven EmLLM chatbot, addresses RQ1 by using peripheral physiological data to interpret users’ stress levels and provide personalized textual responses for stress management. The second example, the Matrix MR application, addresses RQ2 through a context-aware MR system that leverages LLMs and VLMs to analyze the user’s surroundings, recommending and generating interactive everyday 3D objects in real time.
5.1 Prototype 1: physiology-driven EmLLM chatbot for stress management
Based on the EmLLM framework, we developed a prototype chatbot (Figure 2) that passively monitors user physiological signals from the Empatica EmbracePlus smartwatch and provides end-of-day interventions[7]. These signals serve as sensitive, validated, and noninvasive indicators of sympathetic nervous system arousal, making them well suited for detecting short-term affective fluctuations in naturalistic settings compared to other modalities. An end-to-end, multi-channeled one-dimensional convolutional neural network (1D CNN) classifies stress versus non-stress states by separately processing each physiological signal, then pooling, flattening, and concatenating the extracted features to classify states as stressed or non-stressed. Trained and evaluated on the WESAD dataset[53] using a leave-one-subject-out cross-validation approach to ensure robustness across individuals, the model achieves an accuracy of 85.1% and an F1 score of 89. The model was optimized using the Adam optimizer and binary cross-entropy loss.
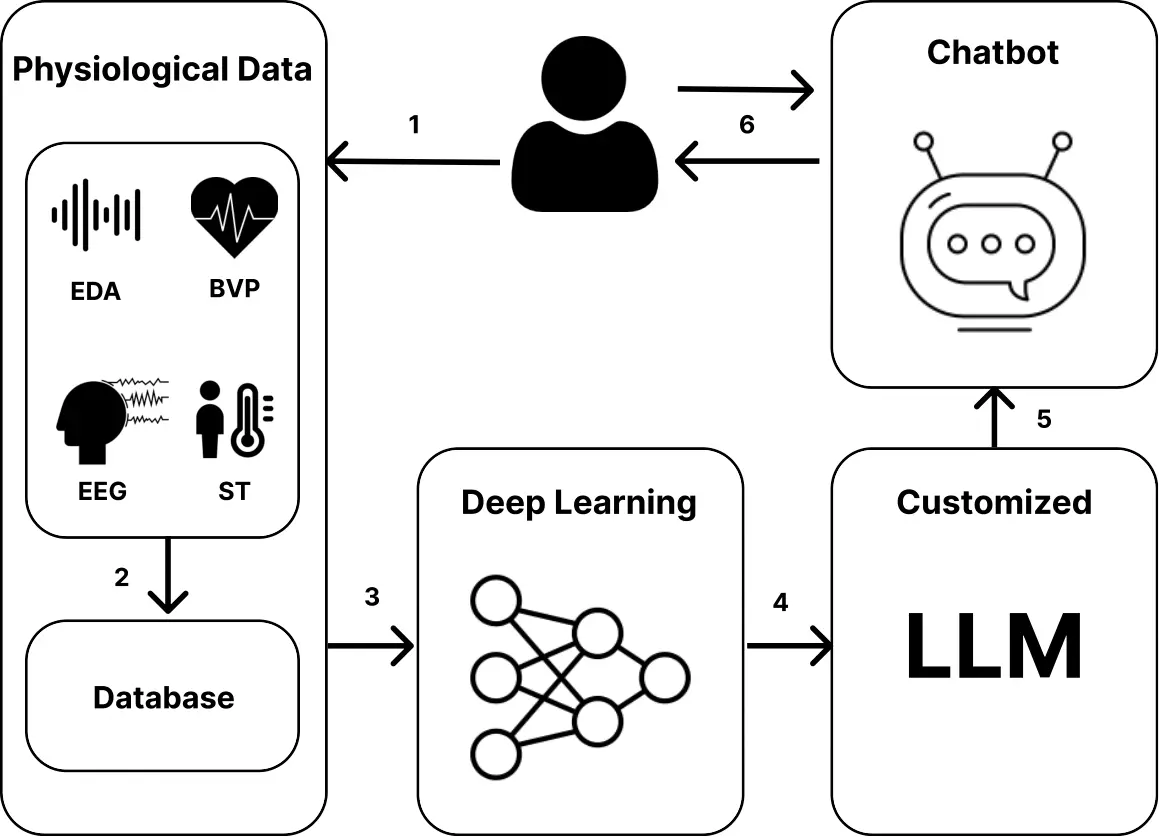
Figure 2. Proposed EmLLM approach. EDA: electrodermal activity; EEG: electroencephalogram; LLM: large language models; BVP: blood volume pulse; ST: skin temperature.
For stress management, we fine-tuned the open-source Falcon-7B LLM[78] using the quantized low-rank adaptation (QLoRA) technique[79] on a dataset collected from mental health support websites. QLoRA reduces model weights to a 4-bit format, significantly lowering memory requirements while maintaining adaptability. We then applied prompt engineering to the fine-tuned model so it behaves like a trained psychologist, follows cognitive behavior therapy principles, and provides clarifications if it cannot answer a query. Finally, we developed a web interface that integrates the stress detection model with the customized Falcon-7B, enabling personalized stress management. The pseudocode for the physiology-driven EmLLM chatbot is presented in Algorithm 1.
5.1.1 Prototype 1: study protocol
We conducted an in-the-wild pilot study in which participants wore the Empatica EmbracePlus smartwatch throughout their workday and interacted with the chatbot at the end of the day. The study evaluated the chatbot’s ability to accurately detect user stress, deliver human-like responses, and provide therapeutic support.
Participants were recruited based on the following inclusion criteria: (1) currently enrolled doctoral students and (2) no history of severe mental health conditions. Doctoral students were chosen as the target population due to their known susceptibility to high cognitive load and chronic stress in academic environments[80,81]. All participants provided informed consent and received training on the use of the smartwatch and the chatbot prior to data collection.
At the beginning of each workday, participants completed a pre-task Short Stress State Questionnaire (SSSQ)[82] and were fitted with the smartwatch. They then resumed their daily academic or professional activities while continuously wearing the device, following instructions to avoid altering its position and to refrain from consuming mood-altering substances or engaging in strenuous exercise.
At the end of the day, participants removed the smartwatch and completed the post-task SSSQ. They then interacted with the EmLLM chatbot for at least 15 minutes. The chatbot greeted each user by name, presented their predicted stress level, and invited them to discuss any stressors they had experienced. After the session, participants completed the Godspeed questionnaire[83], and the Session Rating Scale (SRS)[84] and were encouraged to provide additional feedback.
The SSSQ is an adaptation of the Dundee Stress State Questionnaire that measures engagement, distress, and worry, providing pre- and post-task stress indicators[82]. These indicators were compared with the chatbot’s predictions to validate its accuracy. The Godspeed questionnaire, commonly used in human-robot interaction studies, assessed participants’ perceptions of intelligence, friendliness, and ease of use[83]. The SRS captured users’ subjective experiences of the session by gauging therapeutic alliance, helping evaluate the EmLLM chatbot’s effectiveness as a supportive tool[84].
5.1.2 Prototype 1: results
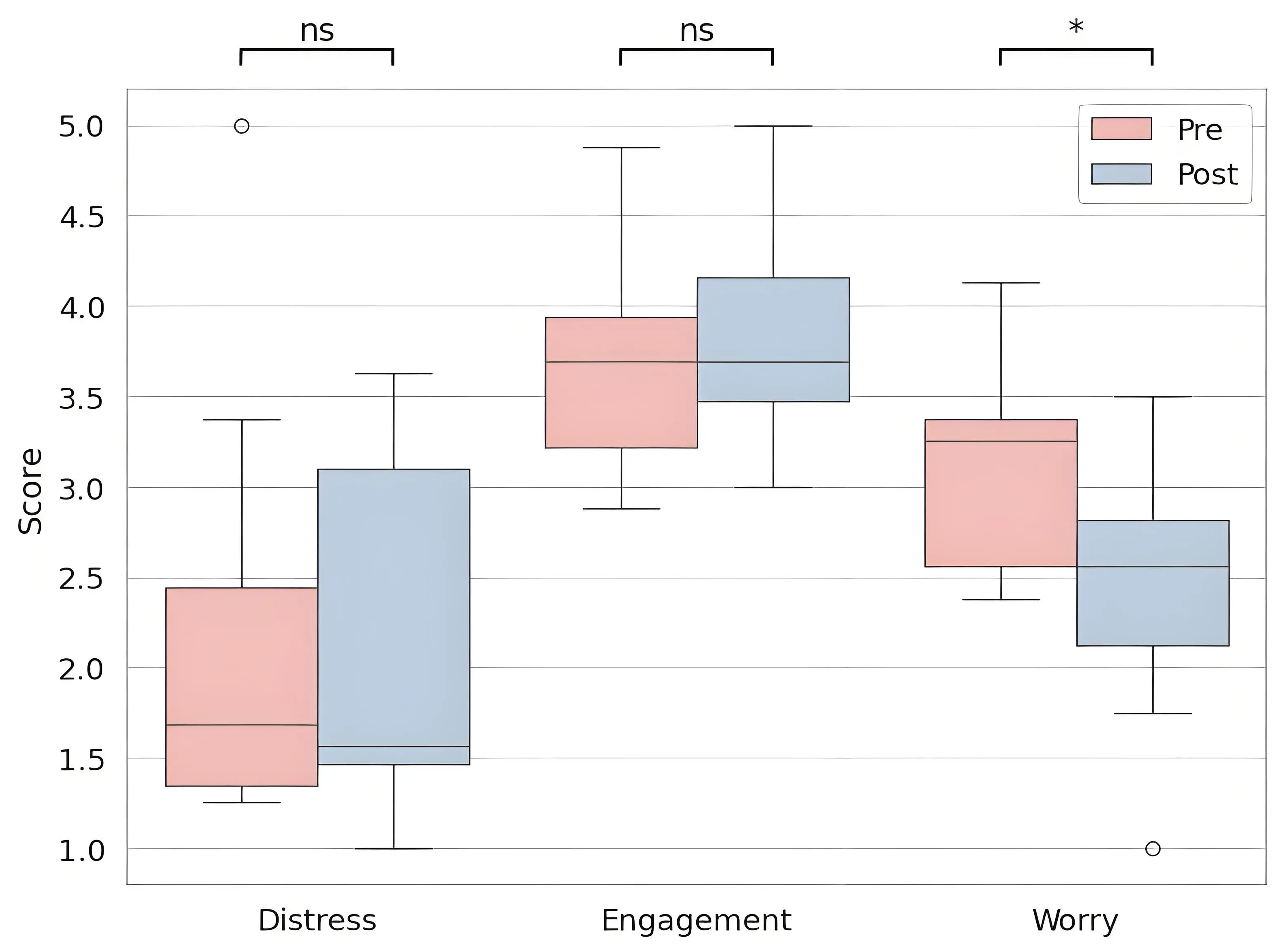
A pilot study was conducted with eight doctoral students (5 men, 3 women; age range 23-37, mean = 30.5). A repeated-measures analysis of the SSSQ data revealed a statistically significant reduction in worry (mean difference ≈ -0.67, p < 0.05), while engagement (≈ 0. 11, p ≈ 0.51) and distress (≈ -0.09, p ≈ 0.78) remained stable (Figure 3). The stress recognition model classified six participants as experiencing stress during the day, which generally aligned with self-reported questionnaire data. Two participants displayed minimal signs of stress; however, one of these participants was clinically diagnosed with attention-deficit hyperactivity disorder (ADHD), and another had a hearing disability, highlighting individual variations in physiological and subjective stress measures.
Regarding the chatbot’s perceived performance, data from the Godspeed questionnaire indicated moderate competence (3.5) and responsiveness (3.63), while human-like responses (2.88), conversational elegance (2.88), and pleasantness (3.0) received comparatively lower ratings. Despite these mixed impressions, the chatbot achieved favorable scores in therapeutic alliance measures: quality (3.25), empathy (3.63), and perceived session relevance (3.75). Participants remarked that the chatbot “asked thought-provoking questions” and “provided helpful context,” often comparing it favorably to more generic AI tools.
However, several users noted that the chatbot occasionally responded in Spanish, likely due to the multilingual content in the training dataset. Some participants also expressed concerns about their data privacy and potential access by third parties. Overall, feedback emphasized the need for further refinement, particularly regarding language consistency, personalization of responses, and data privacy assurances, to fully realize the EmLLM chatbot’s potential as a supportive tool for stress management.
5.2 Prototype 2: matrix MR application for generating everyday 3D objects
The Matrix framework for generating everyday 3D objects in a MR application (Figure 4) includes several key components and processes, each labeled with abbreviations denoting specific functions. Upon entering the MR environment, users are greeted with a welcoming voice message, providing a user-friendly introduction to the system. They are then prompted to select their preferred language from a menu. The system supports approximately 100 languages and is powered by Meta’s SeamlessM4T, ensuring inclusivity and accessibility for a diverse user base.
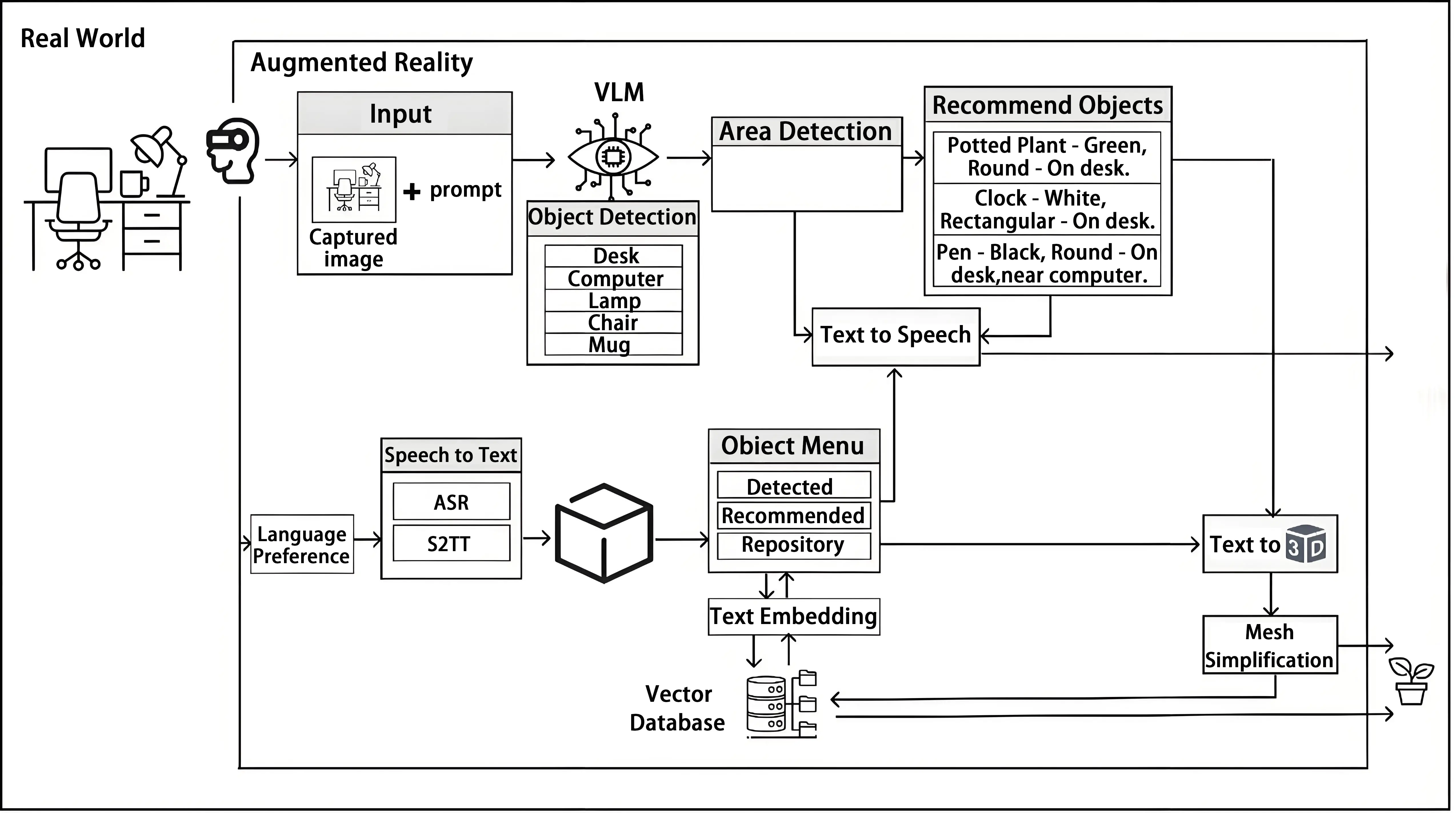
Figure 4. The overview of the Matrix framework and the individual services provided. LLM: large language models; VLM: vision-language models; ASR: automatic speech recognition; S2TT: speech-to-text translation.
To extract meaningful content from the transcribed or translated text, we employ the Llama 2 7B LLM, which identifies objects and their attributes within the user’s commands. For this purpose, we use an optimized implementation of Llama, llama.cpp, designed to run on minimal hardware. This allows the system to operate locally on a wide range of devices, ensuring greater accessibility and flexibility. Additionally, we utilize the LangChain library to extract objects and their attributes, which provides prompt templates for prompt engineering and optimization.
Once the objects are identified and modeled from the transcribed or translated text, the next step is to suggest related objects. This is achieved through an advanced use of the Llama 2 LLM, which processes the extracted object data to generate recommendations. The model considers the context, properties, and functions of the identified objects to suggest items that could logically coexist with or complement the primary objects in the given environment. This process enriches the user experience by providing creative and contextually appropriate options.
Furthermore, users can capture an image of their environment using the headset’s camera, which is then processed by a VLM for object recommendation and generation. This enables the system to suggest contextually relevant objects not currently present in the scene. The recommended objects are subsequently generated and presented to the user as real-time 3D models, enhancing the interactivity and depth of the MR experience. The pseudocode for the Matrix MR application is provided in Algorithm 2.
5.2.1 Prototype 2: study protocol
A total of 35 participants with varying levels of prior exposure to XR technologies were recruited to evaluate the Matrix MR system. To ensure inclusivity, participants ranged from XR novices (first-time users) to those with moderate experience using VR or AR applications. Before the study, all participants received a brief orientation and hands-on tutorial on interacting with objects via voice and gestures within the MR environment. All tasks were conducted in a controlled indoor laboratory setting (Figure 5). Fixed environmental elements included desks, chairs, monitors, and whiteboards.

Figure 5. Context-aware content creation in MR. (a) The user is wearing a HoloLens device in a room environment; (b) The system displays context-aware recommended objects based on the current room setup; (c) The MR view integrates 3D objects generated by a text-to-3D model, seamlessly blending virtual content into the room environment. MR: mixed reality.
Each participant completed a series of tasks designed to demonstrate key system features, including ease of interaction, responsiveness, and overall user experience (Figure 5 and Figure 6). In Task 1, participants generated a simple 3D object using a voice command to test the speech-to-3D pipeline. Task 2 focused on retrieving pre-generated objects from the repository to assess retrieval efficiency. Task 3 involved customizing the placement and size of objects within the MR environment and evaluating the intuitiveness and control of interactions.

Figure 6. (a) Status board example in Matrix MR application. The “what’s happening” board displays the “Matrix offers” message, informing users to choose from requested objects, LLM recommendations, or items from the repository to create a 3D model; (b) A plate containing a banana, apple, and grapes, generated in real-time, is put on a table. MR: mixed reality; LLM: large language models.
Task performance was assessed using five metrics: task completion time, success rate, error rate, system responsiveness, and mesh file size. Task completion time measured the duration required to complete each task, including speech recognition, object generation, and rendering[85]. Success rate tracked the percentage of tasks correctly completed on the first attempt, while error rate recorded issues such as failed object generation or transcription errors[86]. System responsiveness measured the time elapsed between voice input and 3D rendering, a critical factor for maintaining smooth, real-time interaction[87]. Finally, mesh file size compared the size of default Shap-E outputs to that of optimized reduced mesh versions, highlighting the benefits of file optimization in MR environments.
We evaluated the system’s GPU usage and overall performance to understand resource consumption during real-time object generation. Metrics included average GPU utilization, reflecting the percentage of GPU resources consumed; GPU memory consumption, measuring the amount of memory used during object generation[88]; and time to object generation, indicating how long the Shap-E model required to generate a 3D object from a textual prompt[89]. We also assessed the impact of using a pre-generated object repository to improve system efficiency by comparing two scenarios: (1) generating all 3D objects from scratch, and (2) retrieving objects from the existing repository.
We also calculated accuracy metrics for the AI models powering the Matrix MR system, focusing on speech recognition and object generation. Three key metrics were measured: speech-to-text accuracy, reflecting how accurately spoken commands are transcribed; object recognition precision, evaluating the system’s ability to correctly identify and suggest relevant objects; and object rendering fidelity, measuring how closely the generated 3D objects match the user’s original descriptions. Finally, we compared our system with Dream Mesh, a speech-to-3D model generative pipeline in MR[90], in terms of model generation time, consistency, and GPU requirements.
In addition to performance benchmarking, a usability evaluation was conducted to assess user experience and the quality of recommendations. The study involved 35 participants with varying levels of familiarity with MR. Participants interacted with the system’s voice and gesture interfaces to generate, retrieve, and place 3D objects. After the interaction, participants completed a System Usability Scale (SUS) questionnaire. To evaluate the quality of recommendations, we used prompts instructing the system to act as a designer, suggesting five relevant and missing objects (including name, color, shape, and placement) for each scenario. Participants then rated the relevance of these recommendations on a scale from 1 to 5.
5.2.2 Prototype 2: results
Table 1 presents the task performance data, highlighting the benefits of using the reduced mesh size model in terms of system performance and usability. Notably, the median task completion time decreased from approximately 386 seconds with the default Shap-E output to just 122.4 seconds with the reduced mesh model, achieving nearly a threefold improvement (Figure 7). Additionally, the task success rate increased from 76% to 88%, indicating a more reliable and smoother user experience.
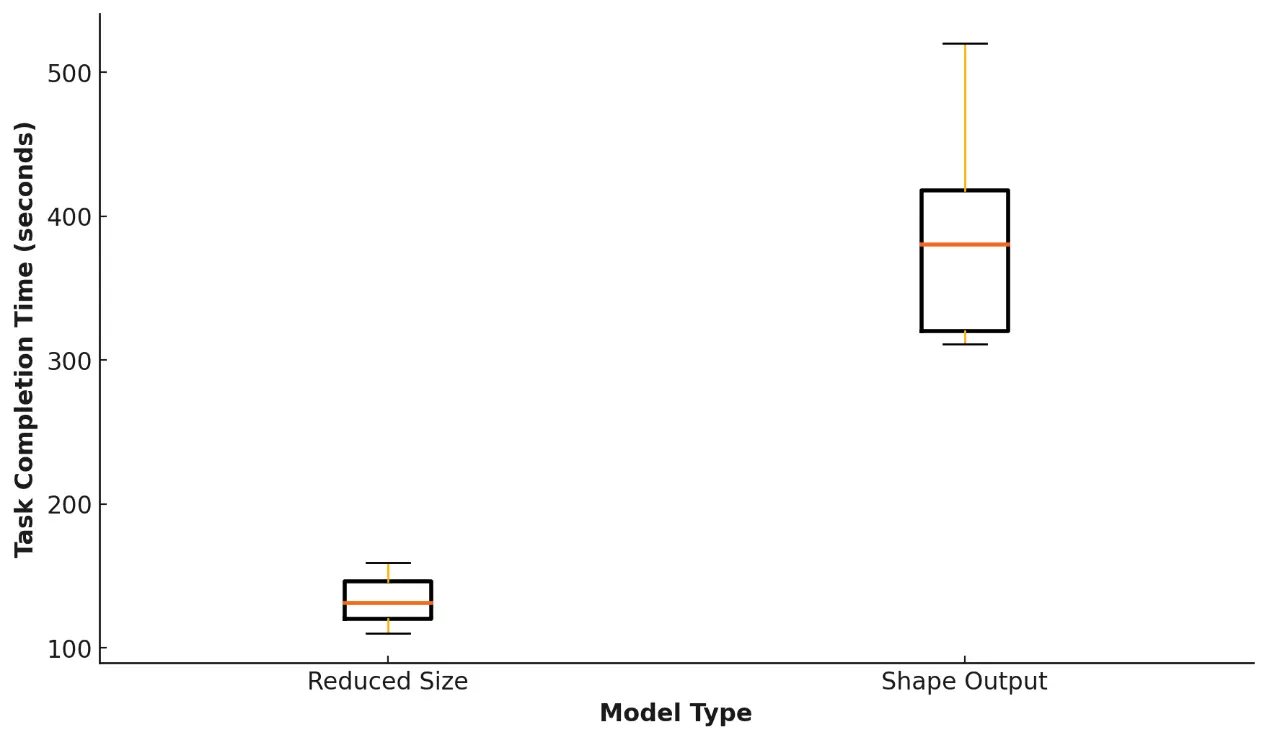
Figure 7. Task completion time for the reduced mesh size model compared to the shape output model.
Table 1. Task performance with default Shap-E model output and reduced mesh size.
| Metric | Shap-E Output | Reduced Size |
| Task Completion Time (seconds) | 386.2 | 122.4 |
| Task Success Rate (%) | 76% | 88% |
| System Error Rate (errors/task) | 0.15 | 0.14 |
| System Responsiveness (seconds) | 282.73 | 74.32 |
| Mesh File Size (MB) | 2.5 | 0.16 |
Despite these improvements, error rates remained consistently low for both models, indicating that performance gains did not compromise accuracy. System responsiveness saw a dramatic enhancement, with the time from voice input to rendered output decreasing from 282.73 seconds to just 74.32 seconds. Additionally, the mesh file size was significantly reduced from 2.5 MB to 0.16 MB, allowing faster load times and improved resource efficiency. These advances make the reduced mesh size model highly suitable for real-time object generation in XR applications.
Table 2 summarizes the GPU and system performance under two conditions: (1) generating 3D objects from scratch, and (2) retrieving them from a pre-generated object repository. When 3D objects were retrieved from the repository rather than generated on demand, average GPU utilization decreased from 54% to 31%. This reduction indicates a lower computational load on the system’s graphics processor, enabling more efficient rendering and interaction. Such efficiency is especially important in real-time MR environments with limited hardware capabilities.
Table 2. GPU and system performance with and without repository integration.
| Metric | No Repo | With Repo |
| Average GPU Utilization (%) | 54% | 31% |
| GPU Memory Consumption (GB) | 6.1 | 2.3 |
| Time to Object Generation (seconds) | 29.60 | 16.32 |
GPU: graphics processing unit.
Similarly, GPU memory consumption decreased from 6.1 GB to just 2.3 GB. Reduced memory usage frees up system resources for other tasks and minimizes the risk of latency or system instability. Beyond these hardware level benefits, the time to generate objects was significantly shortened from 29.60 seconds when generating from scratch to just 16.32 seconds when retrieving from the repository, enabling near instantaneous feedback and smoother task execution in dynamic MR workflows.
Table 3 summarizes the accuracy metrics of the AI models integrated within the Matrix MR system. The speech-to-text model achieved an accuracy of 91%, demonstrating reliable transcription of spoken user commands into text. Object recognition precision reached 85%, indicating the system’s effectiveness in correctly identifying and recommending relevant 3D objects based on the transcribed input. The object rendering fidelity was measured at 87%, reflecting the degree to which the generated 3D objects accurately correspond to the users’ original verbal descriptions. This metric holds particular significance in mixed reality environments, where high visual fidelity directly influences user immersion and task performance.
Table 3. Summary of AI model accuracy metrics.
| Metric | Value |
| Speech-to-Text Accuracy (%) | 91% |
| Object Recognition Precision (%) | 85% |
| Object Rendering Fidelity (%) | 87% |
Table 4 compares the Matrix MR system with Dream Mesh. Dream Mesh, which is based on the DreamFusion model, requires approximately 30 to 40 minutes to generate a single 3D object due to its computationally intensive 10,000-iteration pipeline. In contrast, our Matrix MR system employs the Shap-E model with integrated mesh simplification, enabling object generation in under 50 seconds. Moreover, whereas Dream Mesh shows variability in outputs for the same prompt, our system guarantees consistency by utilizing semantic search combined with a vector database, allowing efficient retrieval and reuse of previously generated models.
Table 4. Comparison of Matrix vs. Dream Mesh.
| Feature | Matrix | Dream Mesh |
| Model Generation Time | < 50 Seconds | 30-40 minutes |
| Model Consistency | Consistent via reuse of objects | Varies with same prompt |
| GPU Requirements | Nvidia Tesla T4, 16GB VRAM | Nvidia 3090Ti, 24GB VRAM |
GPU: graphics processing unit; VRAM: video random access memory.
The Matrix MR system also provides greater accessibility by supporting less powerful hardware. Unlike Dream Mesh, which requires a high-end Nvidia 3090Ti GPU with 24 GB of video random access memory (VRAM), our system is optimized to run efficiently on resource-constrained GPUs such as the Nvidia Tesla T4 with 16 GB of VRAM. Beyond improvements in performance and hardware efficiency, the Matrix MR system incorporates several advanced features not found in Dream Mesh, including an LLM-based object recommendation system, multilingual speech-to-3D generation capabilities, and real-time speech feedback. These enhancements make our system a more scalable, interactive, and user-friendly framework for generating 3D content in XR environments.
In the usability-specific results, the SUS outcomes affirm the system’s ease of use. An average SUS score of 69.64 places the system within the “acceptable” usability range, while scores above 80, as achieved by experienced MR users, fall within the “excellent” bracket. This indicates that the interface and interaction model were particularly intuitive for users already familiar with MR paradigms. Notably, participants with prior experience rated the system higher, with a mean SUS score of 80.71, suggesting a more favorable perception of usability among experienced users. In terms of recommendation quality, the system received an average relevance rating of 4.1 out of 5 from participants.
6. Discussion
6.1 The integrated empathy-enable XR system
A central claim of this study is that achieving genuine empathy in XR requires bridging the gap between XR as an “empathy machine” and XR as an “empathic entity.” We introduced two key frameworks: (1) the EmLLM and (2) the Matrix for XR content generation. The integration of these two frameworks facilitates the development of an Empathy-Enabled XR system capable of understanding users’ affective and cognitive states, taking into account their situational context, and generating XR content that not only evokes empathy in users but also expresses empathy toward them.
The process begins with multimodal sensing and inference. The EmLLM framework collects and interprets multimodal data to derive insights into the user's affective and cognitive states. In parallel, the Matrix framework analyzes the user’s physical environment using image captures or point-cloud data to detect relevant objects, spatial layout, and lighting conditions. The integration of these data streams results in a dynamic user profile that encompasses both internal dimensions (affective and cognitive states) and external dimensions (environmental and contextual factors).
A cohesive Empathy Engine, which runs on LLMs, is central to the architecture. EmLLM’s detection of affective and cognitive states and the Matrix framework’s environment detections can be continuously integrated into a unified decision-making pipeline. This allows the system to reason holistically, balancing the user’s emotional well-being with the spatial opportunities available in their immediate environment. For instance, if the user’s stress level is high and the environment is relatively open, the system might introduce a calming virtual sculpture or ambient lighting effect within the MR experience.
Finally, real-time adaptive output forms the user-facing layer. EmLLM generates empathic text for users based on their affective or cognitive states. The Matrix framework creates 3D objects in real time within the MR environment based on the user’s surrounding context. This integrated solution can sense multimodal data and apply the Empathy Engine to generate objects relevant to the user’s current state and environment. The combination of EmLLM and Matrix provides a solid foundation for truly empathic XR experiences that offer immersion, embodiment, and customization.
This unified framework enables diverse and impactful applications across multiple domains. Empathy-enabled XR can enhance traditional text-based coping strategies in mental health support by dynamically adapting environmental elements such as lighting and soundscapes or by generating calming 3D objects to complement empathic dialogue. For accessibility and inclusive design, the integration of STT, text-to-3D, and scene analysis supports a wide range of communication needs, allowing users with hearing impairments or cognitive challenges to engage more effectively with XR environments.
6.2 AI for empathy-enabled XR
In this section, we discuss the results and their interpretation in relation to the research questions.
6.2.1 AI for empathy-enabled XR inference
The EmLLM prototype demonstrates the feasibility of using physiological sensing combined with a lightweight deep learning model to infer user stress levels in non-clinical, real-world contexts. The significant reduction in worry (SSSQ mean diff ≈ –0.67, p ≤ 0.05) suggests that interactions with the chatbot may have contributed to cognitive-emotional relief, consistent with previous findings that real-time interventions can modulate cognitive stress components[52]. The use of photoplethysmography (PPG), EDA, and ST instead of more invasive biomarkers such as cortisol is justified by their superior temporal resolution, noninvasiveness, and sensitivity to sympathetic arousal[91], which are critical for XR systems requiring continuous and passive monitoring.
Furthermore, EmLLM’s stress recognition model achieved high accuracy (85.1%, F1 = 89) using the WESAD dataset, confirming that convolutional neural network (CNN)-based physiological classifiers can be effectively adapted for wearable-based XR applications. The alignment between model predictions and participants’ self-reported stress levels, despite some variability due to conditions such as ADHD or sensory disabilities, supports the robustness and generalizability of this approach. In the Matrix MR application, incorporating environmental context through VLMsand camera-captured spatial scenes further enhances state-aware reasoning. The VLM’s ability to recommend objects that correspond to the physical scene contributes to environmental context inference, a critical yet often underexplored element of user-centered XR personalization.
6.2.2 AI for empathy-enabled XR customization
The Matrix system demonstrates a context-aware and responsive pipeline for real-time 3D content customization. Significant improvements achieved with the reduced mesh model, such as a threefold faster task completion time, a 12% increase in task success, and a fourfold reduction in rendering time, highlight the critical importance of performance optimization for real-time, immersive experiences. These findings support the hypothesis that XR content generation must be adaptive and computationally efficient to enable seamless user interaction and personalization.
Furthermore, the use of LLMs for object extraction and semantic recommendation introduces a novel approach to dynamically adapting XR content based on verbal descriptions and environmental inputs. The Matrix MR application effectively bridges the gap between user state inference and environmental adaptation by integrating LLM-driven content logic with real-time object rendering.
The system’s STT accuracy 91%, object recognition precision of 85%, and rendering fidelity of 87% further validate the pipeline’s usability and intelligence. Compared to prior systems such as Dream Mesh, which require extensive GPU resources and longer generation times (30 to 40 minutes per object), Matrix provides a scalable and low-latency alternative that supports diverse hardware (e.g., Tesla T4 GPU), multilingual interaction, and object reuse.
6.3 Limitations
While the EmLLM and Matrix prototypes demonstrate promising results for affective inference and adaptive content generation in XR, several limitations must be acknowledged. For Prototype 1, a physiology-driven EmLLM chatbot designed for stress management, limitations include the validity and reliability of the stress detection model, as well as the chatbot’s limited ability to reduce affective arousal. The stress detection model was trained on the WESAD dataset[53], which captures stress through induced laboratory stimuli such as public speaking and arithmetic tasks. These conditions may not fully capture the complexity of stressors encountered in academic or occupational environments, potentially limiting the ecological validity of the model’s predictions in real-world scenarios. Furthermore, the model’s reliability remains challenging due to the high sensitivity of physiological signals to noise, sensor displacement, and individual variability. Although the chatbot achieved a statistically significant reduction in users’ worry, it had minimal impact on distress and engagement, suggesting greater effectiveness in alleviating cognitive symptoms of stress than affective arousal.
Prototype 2, the Matrix system for generating everyday objects in MR, has limitations related to rendering fidelity, object recognition bias, and real-world deployment. While the Matrix system outperforms earlier pipelines such as DreamFusion in latency and hardware efficiency, its rendering fidelity may not yet reach the level of those models. Additionally, the object recognition and suggestion pipelines, particularly those based on LLMs and VLMs, may be influenced by cultural bias in interpreting everyday objects. For example, items recommended for a Western office setting may not accurately reflect the lived environments or expectations of users from other cultural backgrounds. Furthermore, although the Matrix framework is optimized to run on mid-range GPUs like the Tesla T4, real-time deployment on consumer grade edge devices such as AR glasses or smartphones remains challenging. The complexity of real-world environments also places demand on the Matrix system, especially in cluttered or dynamic settings where overlapping objects and limited computational resources can impede real-time performance on mobile XR devices.
6.4 Future works
Future research can pursue several strategic directions, particularly aimed at addressing the limitations discussed above. To improve the ecological validity and reliability of the stress detection model in Prototype 1, training the model on in-the-wild datasets such as the K-EmoPhone dataset[92], or datasets that simulate real-world scenarios like the SWELL knowledge ork (SWELL-KW) dataset[93], is recommended. The K-EmoPhone dataset[92] collected multimodal physiological data from 77 students over seven days in real-world contexts. The SWELL-KW dataset[93] gathered heart rate and skin conductance data from 25 participants engaged in knowledge work tasks such as report writing, presentations, and email reading. Additionally, developing personalized models[94] and implementing personalized calibration routines[95] can account for interpersonal variability. Researchers are also investigating self-supervised learning[96] and reinforcement learning[97] approaches to enhance the ecological validity and reliability of such models. To improve the chatbot’s effectiveness in addressing affective arousal, future versions will focus on integrating emotion-regulation strategies, including breathing guidance, mindfulness practices, and reflective prompts.
For Prototype 2, enhancing the visual fidelity of generated 3D content without compromising performance may involve a hybrid rendering approach that combines lightweight mesh generation with cloud-based upscaling or progressive detail refinement. To enable scalability and deployment on edge devices, techniques such as model pruning, quantization, and distillation can be explored to reduce resource demands. Furthermore, fallback mechanisms that allow the system to prioritize essential interactions under constrained computational resources could be incorporated to ensure robustness on mobile and wearable XR platforms. To improve performance in cluttered or dynamic environments, an enhanced VLM pipeline incorporating spatial reasoning modules and scene segmentation techniques can be developed to better differentiate overlapping or partially occluded objects. Environment-aware caching of frequently used 3D assets may also help reduce rendering delays. To address LLM hallucinations and ensure safety, response verification layers and context-grounded generation strategies could be implemented, utilizing structured knowledge graphs or predefined object libraries.
Future developments may also include advanced multimodal fusion techniques to integrate physiological signals and environmental context more effectively, thereby enabling richer, higher-order inference of user affect, cognition, and surroundings. A key direction involves generating multimodal data for empathic interactions within the unified framework, allowing the system to dynamically produce a combination of verbal (text or speech), visual (3D objects, ambient lighting), and haptic feedback (vibrations, tactile cues) aligned with the user’s emotional state and context. To support reproducibility and comparability, future research should focus on developing standardized benchmarks for empathy-enabled XR systems. These benchmarks would evaluate real-time affective inference accuracy, latency under mobile and edge computing constraints, and subjective user experience metrics such as perceived empathy and trust. Finally, to address privacy and ethical concerns, future work must adhere to privacy-by-design principles, including on-device data processing, differential privacy, and explicit consent workflows.
7. Conclusion
This paper presents two complementary frameworks, EmLLM and Matrix, designed to enable affect-aware and adaptive experiences in XR. We detailed the design, implementation, and evaluation of two working prototypes: a physiology-driven EmLLM chatbot for daily stress management, and a Matrix-based MR application capable of generating everyday 3D objects in real time.
Evaluation results demonstrated strong performance and user impact for both prototypes. The EmLLM stress detection model achieved an accuracy of 85.1% and contributed to a significant reduction in worry scores (p ≤ 0.05), indicating effective relief of cognitive stress. The Matrix system showed a threefold improvement in task completion time and increased the task success rate from 76% to 88%, while maintaining high object recognition precision (85%) and rendering fidelity (87%). These findings underscore the effectiveness of combining affective inference with adaptive content generation within XR environments.
Together, EmLLM and Matrix illustrate the potential of empathy-enabled XR systems that adapt in real time to users’ mental states and contextual environments. This integration opens new frontiers for immersive, human-centered applications across mental health, collaborative training, education, and personalized productivity. Although challenges remain particularly concerning physiological signal variability, content safety, and privacy, this work establishes a foundation for the future development of empathy-enabled XR systems.
Authors contribution
Dongre P, Behravan M: Ideation, methodology, data analysis, writing.
Gračanin D: Ideation, review, editing, supervision, writing original draft.
All authors approved the final version of the manuscript.
Conflicts of interest
All authors declared that there are no conflicts of interest.
Ethical approval
The studies were approved by Virginia Tech Institutional Review Board #24-1072
Consent to participate
All participants provided a freely-given, informed consent to participate in the studies.
Consent for publication
Not applicable.
Availability of data and materials
The datasets used in this study are publicly available, and the source code for the Matrix MR application for everyday object recognition and generation is available at: https://github.com/MjBehravan/Matrix/
Funding
None.
Copyright
©The Author(s) 2025.
References
-
1. Piumsomboon T, Lee Y, Lee GA, Dey A, Billinghurst M. Empathic mixed reality: Sharing what you feel and interacting with what you see. In: 2017 International Symposium on Ubiquitous Virtual Reality (ISUVR); 2017 Jun 27-29; Nara, Japan. New York: IEEE; 2017. p. 38-41.
[DOI] -
2. Loveys K, Sagar M, Billinghurst M, Saffaryazdi N, Broadbent E. Exploring empathy with digital humans. In: 2022 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW); 2022 Mar 12-16; Christchurch, New Zealand. New York: IEEE; 2022. p. 233-237.
[DOI] -
3. Gračanin D, Lasisi RO, Azab M, Eltoweissy M. Next generation smart built environments: The fusion of empathy, privacy and ethics. In: 2019 First IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA); 2019 Dec 12-14; Los Angeles: USA. New York: IEEE; 2019. p. 260-267.
[DOI] -
4. Gračanin D, Park J, Eltoweissy M. XR-CEIL: Extended reality for cybersecurity experiential and immersive learning. In: Stephanidis C, Antona M, Ntoa S, editors. HCI International 2022 Posters: 24th International Conference on Human-Computer Interaction, HCII 2022 Virtual Event. Cham: Springer; 2022. p. 487-492.
[DOI] -
5. Wienrich C, Latoschik ME. Extended artificial intelligence: New prospects of human-AI interaction research. Front Virtual Real. 2021;2:686783.
[DOI] -
6. Vergara D, Lampropoulos G, Antón-Sancho Á, Fernández-Arias P. Impact of artificial intelligence on learning management systems: A bibliometric review. Multimodal Technol Interact. 2024;8(9):75.
[DOI] -
7. Dongre P, Behravan M, Gupta K, Billinghurst M, Gračanin D. Integrating physiological data with large language models for empathic human-AI interaction. arXiv:2404.15351 [Preprint] 2024;
[DOI] -
8. Neupane S, Dongre P, Gracanin D, Kumar S. Wearable meets LLM for stress management: A duoethnographic study integrating wearable-triggered stressors and LLM chatbots for personalized interventions. In: Yamashita N, Evers V, Yatani K, Ding X, editors. Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems; 2025 Apr 26-2025 May 1; Yokohama, Japan. New York: Association for Computing Machinery; 2025. p. 1-8.
[DOI] -
9. Dwivedi R, Elluri L. Exploring generative artificial intelligence research: A bibliometric analysis approach. IEEE Access. 2024;12:119884-119902.
[DOI] -
10. Herrera F, Bailenson J, Weisz E, Ogle E, Zaki J. Building long-term empathy: A large-scale comparison of traditional and virtual reality perspective-taking. PLoS One. 2018;13(10):e0204494.
[DOI] -
11. Tong X, Gromala D, Ziabari SPK, Shaw CD. Designing a virtual reality game for promoting empathy toward patients with chronic pain: feasibility and usability study. JMIR Serious Games. 2020;8(3):e17354.
[DOI] -
12. Manuel M, Dongre P, Alhamadani A, Gračanin D. Supporting embodied and remote collaboration in shared virtual environments. In: Chen JYC, Fragomeni G, editors. Virtual, Augmented and Mixed Reality. Cham: Springer; 2021. p. 639-652.
[DOI] -
13. Dey A, Chen H, Hayati A, Billinghurst M, Lindeman RW. Sharing manipulated heart rate feedback in collaborative virtual environments. In: 2019 IEEE International Symposium on Mixed and Augmented Reality (ISMAR); 2019 Oct 14-18; Beijing, China. New York: IEEE; 2019. p. 248-257.
[DOI] -
14. Masai K, Kunze K, Sugimoto M, Billinghurst M. Empathy glasses. In: Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems; 2016 May 7-12; San Jose California, USA. New York: Association for Computing Machinery; 2016. p. 1257-1263.
[DOI] -
15. Bai H, Sasikumar P, Yang J, Billinghurst M. A user study on mixed reality remote collaboration with eye gaze and hand gesture sharing. In: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems; 2020 Apr 25-30; Honolulu, USA. New York: Association for Computing Machinery; 2020. p. 1-13.
[DOI] -
16. Jing A, May K, Matthews B, Lee G, Billinghurst M. The impact of sharing gaze behaviours in collaborative mixed reality. In: Nichols J, editor. Proceedings of the ACM on Human-Computer Interaction; New York: Association for Computing Machinery; 2022. p. 1-27.
[DOI] -
17. Adiani D, Itzkovitz A, Bian D, Katz H, Breen M, Hunt S, et al. Career interview readiness in virtual reality (CIRVR): a platform for simulated interview training for autistic individuals and their employers. ACM Trans Access Comput. 2022;15(1):1-28.
[DOI] -
18. Reidy L, Chan D, Nduka C, Gunes H. Facial electromyography-based adaptive virtual reality gaming for cognitive training. In: Proceedings of the 2020 International Conference on Multimodal Interaction; 2020 Oct 25-29; Netherlands. New York: Association for Computing Machinery; 2020. p. 174-183.
[DOI] -
19. Téllez AM, Castro LA, Tentori M. Developing and evaluating a virtual reality videogame using biofeedback for stress management in sports. Interact Comput. 2023;35(2):407-420.
[DOI] -
20. Dongre P, Gračanin D, Mohan S, Mostafavi S, Ramea K. Modeling and simulating thermostat behaviors of office occupants: are values more important than comfort? In: Proceedings of the 9th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation; 2022 Nov 9-10; New York, United States. New York: Association for Computing Machinery; 2022. p. 488-491.
[DOI] -
21. Mohammadrezaei E, Ghasemi S, Dongre P, Gračanin D, Zhang H. Systematic review of extended reality for smart built environments lighting design simulations. IEEE Access. 2024;12:17058-17089.
[DOI] -
22. Dongre P, Roofigari-Esfahan N. Occupant-building interaction (obi) model for university buildings. In: International Conference on Smart Infrastructure and Construction 2019 (ICSIC) Driving data-informed decision-making. London: ICE Publishing; 2019. p. 631-637.
[DOI] -
23. Dasgupta A, Manuel M, Mansur RS, Nowak N, Gračanin D. Towards real time object recognition for context awareness in mixed reality: A machine learning approach. In: Proceedings of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW). 2020 Mar 22-26;Atlanta, USA New York:IEEE.
[DOI] -
24. Dongre P, Manuel M, Gračanin D. Re-imagining indoor space utilization in the covid-19 pandemic with smart re-configurable spaces (SReS). In: Streitz N, Konomi S, eritors. Distributed, Ambient and Pervasive Interactions. Cham: Springer; 2021. p. 85-99.
[DOI] -
25. Orozco-Mora CE, Fuentes-Aguilar RQ, Hernández-Melgarejo G. Dynamic difficulty adaptation based on stress detection for a virtual reality video game: A pilot study. Electronics. 2024;13(12):2324.
[DOI] -
26. Petrescu L, Petrescu C, Mitrut O, Moise G, Moldoveanu A, Moldoveanu F, et al. Integrating biosignals measurement in virtual reality environments for anxiety detection. Sensors. 2020;20(24):7088.
[DOI] -
27. Ding C, Guo Z, Chen Z, Lee RJ, Rudin C, Hu X. Siamquality: a ConvNet-based foundation model for photoplethysmography signals. Physiol Meas. 2024;45(8):085004.
[DOI] -
28. Zhao YD, Liu YK, Zheng WL, Lu BL. EEG data augmentation for emotion recognition using diffusion model. In: 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC); 2024 Jul 15-19; Orlando, USA. New York: IEEE; 2020. p. 1-4.
[DOI] -
29. Cheng Z, Cheng ZQ, He JY, Sun J, Wang K, Lin Y, et al. Emotion-LLama: Multimodal emotion recognition and reasoning with instruction tuning. arXiv:2406.11161 [Preprint] 2024;
[DOI] -
30. Yan F, Yu P, Chen X. LTNER: Large language model tagging for named entity recognition with contextualized entity marking. In: Antonacopoulos A, Chaudhuri S, Chellappa R, Liu CL, Bhattacharya S, Pal U, editors. Pattern Recognition. Cham: Springer; 2024. p. 399-411.
[DOI] -
31. Shen Y, Tan Z, Wu S, Zhang W, Zhang R, Xi Y, et al. PromptNER: Prompt locating and typing for named entity recognition. In: Rogers A, Boyd-Graber J, Okazaki N, editors. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Toronto: Association for Computational Linguistics; 2023. p. 12492-12507.
[DOI] -
32. Sorin V, Brin D, Barash Y, Konen E, Charney A, Nadkarni G, et al. Large language models and empathy: Systematic review. J Med Internet Res. 2024;26:e52597.
[DOI] -
33. Poole B, Jain A, Barron JT, Mildenhall B. DreamFusion: Text-to-3D using 2D diffusion. arXiv:2209.14988 [Preprint] 2022;
[DOI] -
34. Hono Y, Mitsuda K, Zhao T, Mitsui K, Wakatsuki T, Sawada K. Integrating pre-trained speech and language models for end-to-end speech recognition. In: Ku LW, Martins A, Srikumar V. editors. Findings of the Association for Computational Linguistics: ACL 2024. Thailand: Association for Computational Linguistics; 2024. p. 13289-13305.
[DOI] -
35. Barrault L, Chung YA, Meglioli MC, Dale D, Dong N, Duquenne PA, et al. Seamlessm4t: Massively multilingual & multimodal machine translation. arXiv:2308.11596v3 [Preprint] 2023;
[DOI] -
36. Behravan M, Mohammadrezaei E, Azab M, Gračanin D. Multilingual standalone trustworthy voice-based social network for disaster situations. In: 2024 IEEE 15th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON); 2024 Oct 17-19; Yorktown Heights, USA. New York: IEEE; 2024. p. 264-270.
[DOI] -
37. Hu Y, Chen C, Yang CHH, Li R, Zhang D, Chen Z, et al. GenTranslate: Large language models are generative multilingual speech and machine translators. In: Ku LW, Martins A, Srikumar V, editors. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics; Bangkok: Association for Computational Linguistics; 2024. p. 74-90.
[DOI] -
38. Hu S, Zhou L, Liu S, Chen S, Meng L, Hao H, et al. WavLLM: Towards robust and adaptive speech large language model. In: Al-Onaizan Y, Bansal M, Chen YN, editors. Findings of the Association for Computational Linguistics: EMNLP 2024. Miami: Association for Computational Linguistics; 2024. p. 4552-4572.
[DOI] -
39. Druckmann S, Benster T, Wilson G, Elisha R, inventor; Stanford University, assignee. Speech decoding applications of multimodal machine learning. International Publication WO 2025/076547.
-
40. Zhang X, Liu H, Xu K, Zhang Q, Liu D, Ahmed B, et al. When LLMs meets acoustic landmarks: An efficient approach to integrate speech into large language models for depression detection. arXiv:2402.13276 [Preprint] 2024;
[DOI] -
41. Kim S, Kang H, Choi S, Kim D, Yang M, Park C. Large language models meet collaborative filtering: An efficient all-round llm-based recommender system. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining; 2024 Aug 25-29; Barcelona, Spain. New York: Association for Computing Machinery; 2024. p. 1395-1406.
[DOI] -
42. Cao Y, Mehta N, Yi X, Keshavan RH, Heldt L, Hong L, et al. Aligning large language models with recommendation knowledge. In: Duh K, Gomez H, Bethard S, editors. Findings of the Association for Computational Linguistics: NAACL 2024. Mexico: Association for Computational Linguistics; 2024. p. 1051-1066.
[DOI] -
43. Mittal P, Cheng YC, Singh M, Tulsiani S. AutoSDF: Shape priors for 3D completion, reconstruction and generation. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022 Jun 18-24; New Orleans, USA. New York: IEEE; 2022. p. 306-315.
[DOI] -
44. Fu R, Zhan X, Chen Y, Ritchie D, Sridhar S. ShapeCrafter: A recursive text-conditioned 3D shape generation model. arXiv:2207.09446 [Preprint] 2022;
[DOI] -
45. Cheng YC, Lee HY, Tulyakov S, Schwing A, Gui L. SDFusion: Multimodal 3D shape completion, reconstruction, and generation. arXiv:2212.04493 [Preprint] 2022;
[DOI] -
46. Li M, Duan Y, Zhou J, Lu J. Diffusion-SDF: Text-to-shape via voxelized diffusion. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023 Jun 17-24; Vancouver, Canada. New York: IEEE; 2023. p. 12642-12651.
[DOI] -
47. Zhao Z, Liu W, Chen X, Zeng X, Wang R, Cheng P, et al. Michelangelo: Conditional 3D shape generation based on shape-image-text aligned latent representation. arXiv:2306.17115 [Preprint] 2023;
[DOI] -
48. Jun H, Nichol A. Shap-E: Generating conditional 3d implicit functions. arXiv:2305.02463 [Preprint] 2017;
[DOI] -
49. Tian X, Yang YL, Wu Q. ShapeScaffolder: Structure-aware 3D shape generation from text. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV); 2023 Oct 1-6; Paris, France. New York: IEEE; 2023. p. 2715-2724.
[DOI] -
50. Koo J, Yoo S, Nguyen MH, Sung M. Salad: Part-level latent diffusion for 3D shape generation and manipulation. arXiv:2303.12236 [Preprint] 2023;
[DOI] -
51. Gračanin D. Immersion versus embodiment: Embodied cognition for immersive analytics in mixed reality environments. In: Schmorrow DD, Fidopiastis CM, editors. Augmented Cognition: Intelligent Technologies. Cham: Springer; 2018. p. 355-368.
[DOI] -
52. Fairclough SH. Fundamentals of physiological computing. Interact Comput. 2009;21(1-2):133-145.
[DOI] -
53. Schmidt P, Reiss A, Duerichen R, Marberger C, Van Laerhoven K. Introducing WESAD, a multimodal dataset for wearable stress and affect detection. In: Proceedings of the 20th ACM International Conference on Multimodal Interaction; 2018 Oct 16-20; Boulder, USA. New York: Association for Computing Machinery; 2018. p. 400-408.
[DOI] -
54. Hickey BA, Chalmers T, Newton P, Lin CT, Sibbritt D, McLachlan CS, et al. Smart devices and wearable technologies to detect and monitor mental health conditions and stress: A systematic review. Sensors. 2021;21(10):3461.
[DOI] -
55. Hilty DM, Armstrong CM, Luxton DD, Gentry MT, Krupinski EA. A scoping review of sensors, wearables, and remote monitoring for behavioral health: uses, outcomes, clinical competencies, and research directions. J Technol Behav Sci. 2021;6:278-313.
[DOI] -
56. Gedam S, Paul S. A review on mental stress detection using wearable sensors and machine learning techniques. IEEE Access. 2021;9:84045-84066.
[DOI] -
57. Gupta K, Lazarevic J, Pai YS, Billinghurst M. AffectivelyVR: Towards VR personalized emotion recognition. In: Proceedings of the 26th ACM Symposium on Virtual Reality Software and Technology; 2020 Nov 1-4; Canada. New York: Association for Computing Machinery; 2020. p. 1-3.
[DOI] -
58. Mirsamadi S, Barsoum E, Zhang C. Automatic speech emotion recognition using recurrent neural networks with local attention. In: 2017 IEEE International conference on acoustics, speech and signal processing (ICASSP); 2017 Mar 5-9; New Orleans, USA. New York: IEEE; 2020. p. 2227-2231.
[DOI] -
59. Wang M, Deng W. Deep face recognition: A survey. Neurocomputing. 2021;429:215-244.
[DOI] -
60. Zeng Z, Pantic M, Roisman GI, Huang TS. A survey of affect recognition methods: Audio, visual, and spontaneous expressions. IEEE Trans Pattern Anal Mach Intell. 2009;31(1):39-58.
[DOI] -
61. Mehta D, Sridhar S, Sotnychenko O, Rhodin H, Shafiei M, Seidel HP, et al. VNect: Real-time 3D human pose estimation with a single RGB camera. ACM Trans Graph. 2017;36(4):1-14.
[DOI] -
62. Barros P, Magg S, Weber C, Wermter S. A multichannel convolutional neural network for hand posture recognition. In: Wermter S, Weber C, Duch W, Honkela T, Koprinkova-Hristova P, Magg S, Palm G, Villa AEP, eitors. Artificial Neural Networks and Machine Learning - ICANN 2014; 2014 Sep 15-19; Hamburg, Germany. Cham: Springer; 2014. p. 403-410.
-
63. Ismail Fawaz H, Forestier G, Weber J, Idoumghar L, Muller PA. Deep learning for time series classification: A review. Data Min Knowl Disc. 2019;33(4):917-963.
[DOI] -
64. Zhao B, Lu H, Chen S, Liu J, Wu D. Convolutional neural networks for time series classification. J Syst Eng Electron. 2017;28(1):162-169.
[DOI] -
65. Yao S, Hu S, Zhao Y, Zhang A, Abdelzaher T. Deepsense: A unified deep learning framework for time-series mobile sensing data processing. In: Proceedings of the 26th international conference on world wide web; 2017 Apr 3-7; Perth, Australia. Switzerland: International World Wide Web Conferences Steering Committee; 2017. p. 351-360.
[DOI] -
66. Du Q, Gu W, Zhang L, Huang SL. Attention-based LSTM-CNNs for time-series classification. In: Proceedings of the 16th ACM conference on embedded networked sensor systems; 2018 Nov 4-7; Shenzhen, China. New York: Association for Computing Machinery; 2018. p. 410-411.
[DOI] -
67. Poria S, Cambria E, Bajpai R, Hussain A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf Fusion. 2017;37:98-125.
[DOI] -
68. Zheng Y, Liu Q, Chen E, Ge Y, Zhao JL. Time series classification using multi-channels deep convolutional neural networks. In: Li F, Li G, Hwang S, Yao B, Zhang Z, editors. Web-Age Information Management. WAIM 2014. Lecture Notes in Computer Science; 2014 Jun 16-18; Macau, China. Cham: Springer; 2014. p. 298-310.
[DOI] -
69. Caruana R. Multitask learning. Mach Learn. 1997;28:41-75.
[DOI] -
70. Mansourian N, Pourshoghi A, Acharya A, Li B. ECG-EmotionNet: Nested mixture of expert (NMoE) adaptation of ECG-foundation model for driver emotion recognition. arXiv:2503.01750 [Preprint]. 2025. Available from: https://arxiv.org/html/2503.01750v1
-
71. White J, Fu Q, Hays S, Sandborn M, Olea C, Gilbert H, et al. A prompt pattern catalog to enhance prompt engineering with Chatgpt. arXiv:2302.11382 [Preprint] 2023;
[DOI] -
72. Lee YK, Lee I, Shin M, Bae S, Hahn S. Chain of empathy: Enhancing empathetic response of large language models based on psychotherapy models. arXiv:2311.04915 [Preprint] 2023;
[DOI] -
73. Lai T, Shi Y, Du Z, Wu J, Fu K, Dou Y, et al. Supporting the demand on mental health services with AI-based conversational large language models (LLMs). BioMedInformatics. 2024;4:8-33.
[DOI] -
74. Belyaeva A, Cosentino J, Hormozdiari F. Multimodal llms for health grounded in individual-specific data. In: Maier AK, Schnabel JA, Tiwari P, Stegle O, editors. Machine Learning for Multimodal Healthcare Data. Cham: Springer; 2023. p. 86-102.
[DOI] -
75. Behravan M, Matković K, Gračanin D. Generative AI for context-aware 3D object creation using vision-language models in augmented reality. In: 2025 IEEE International Conference on Artificial Intelligence and eXtended and Virtual Reality (AIxVR); 2025 Jan 27-29; Lisbon, Portugal. New York: IEEE; 2025. p. 73-81.
[DOI] -
76. Behravan M, Gračanin D. From voices to worlds: Developing an AI-powered framework for 3D object generation in augmented reality. In: 2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW); 2025 Mar 8-12; Saint Malo, France. New York: IEEE; 2025. p. 150-155.
[DOI] -
77. Behravan M, Haghani M, Gračanin D. Transcending dimensions using generative AI: Real-time 3D model generation in augmented reality. In: Chen JYC, Fragomeni G, editors. Virtual, Augmented and Mixed Reality. Springer Nature Switzerland. HCII 2025. Lecture Notes in Computer Science; 2025 Jun 22-27; Gothenburg, Sweden. Cham: Springer; 2025. p. 13-32.
[DOI] -
78. Almazrouei E, Alobeidli H, Alshamsi A, Cappelli A, Cojocaru R, Debbah M, et al. The falcon series of open language models. arXiv:2311.16867 [Preprint] 2023;
[DOI] -
79. Dettmers T, Pagnoni A, Holtzman A, Zettlemoyer L. QLoRA: Efficient finetuning of quantized LLMs. arXiv:2305.14314 [Preprint] 2023;
[DOI] -
80. Satinsky EN, Kimura T, Kiang MV, Abebe R, Cunningham S, Lee H, Lin X, et al. Systematic review and meta-analysis of depression, anxiety, and suicidal ideation among Ph. D. students. Sci Rep. 2021;11:14370.
[DOI] -
81. Roofigari-Esfahan N, Morshedzadeh E, Dongre P. A conceptual framework for designing interactive human-centred building spaces to enhance user experience in specific-purpose buildings. arXiv:2308.14876 [Preprint] 2023;
[DOI] -
82. Helton WS, Näswall K. Short stress state questionnaire. Eur J Psychol Assess. 2015;31(1):20-30.
[DOI] -
83. Bartneck C. Godspeed questionnaire series: Translations and usage. In: Krägeloh CU, Alyami M, Medvedev ON, editors. International Handbook of Behavioral Health Assessment. Cham: Springer; 2023. p. 1-35.
[DOI] -
84. Duncan BL, Miller SD, Sparks JA. The session rating scale: Preliminary psychometric properties of a “working” alliance measure. J Brief Ther. 2003;3(1):3-12. Available from: http://scottdmiller.com/wp-content/uploads/documents/SessionRatingScale-JBTv3n1.pdf
-
85. Raj S, Murthy LRD, Shanmugam T, Kumar G, Chakrabarti A, Biswas P. Augmented reality and deep learning based system for assisting assembly process. J Multimodal User Interfaces. 2024;18:119-133.
[DOI] -
86. Lee M, Billinghurst M, Baek W, Green R, Woo W. A usability study of multimodal input in an augmented reality environment. Virt Real. 2013;17:293-305.
[DOI] -
87. Bi J, Nguyen N, Vosoughi A, Xu C. Misar: A multimodal instructional system with augmented reality. arXiv:2310.11699 [Preprint] 2023;
[DOI] -
88. Liu Z, Tang H, Lin Y, Han S. Point-voxel CNN for efficient 3D deep learning. In: Wallach HM, Larochelle P, Beygelzimer A, d’Alché-Buc F, Fox EB, editors. Proceedings of the 33rd International Conference on Neural Information Processing Systems; 2019 Dec 8-14; Vancouver, Canada. United States: Curran Associates Inc.; 2019. p. 965-975. Available from: https://pdfs.semanticscholar.org/db56/e976cb14a36992bfccc18e28365ef4cad126.pdf
-
89. Kästner L, Eversberg L, Mursa M, Lambrecht J. Integrative object and pose to task detection for an augmented-reality-based human assistance system using neural networks. In: 2020 IEEE Eighth International Conference on Communications and Electronics (ICCE); 2021 Jan 13-15; Phu Quoc Island, Vietnam. New York: IEEE; 2021. p. 332-337.
[DOI] -
90. Weng SCC, Chiou YM, Do EYL. Dream Mesh: A speech-to-3D model generative pipeline in mixed reality. In: Proceedings of the 2024 IEEE International Conference on Artificial Intelligence and eXtended and Virtual Reality (AIxVR); 2024 Jan 17-19; Los Angeles, USA. New York: IEEE; 2024. p. 345-349.
[DOI] -
91. Boucsein W. Electrodermal Activity. 2nd ed. Boston: Springer; 2012.
-
92. Kang S, Choi W, Park CY, Cha N, Kim A, Khandoker AH, editors . K-emophone: A mobile and wearable dataset with in-situ emotion, stress, and attention labels. Sci Data. 2023;10:351.
[DOI] -
93. Koldijk S, Sappelli M, Verberne S, Neerincx MA, Kraaij W. The swell knowledge work dataset for stress and user modeling research. In: Proceedings of the 16th international conference on multimodal interaction; 2014 Nov 12-16; Istanbul, Turkey. New York: Association for Computing Machinery; 2014. p. 291-298.
[DOI] -
94. Tazarv A, Labbaf S, Reich SM, Dutt N, Rahmani AM, Levorato M. Personalized stress monitoring using wearable sensors in everyday settings. In: 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC); 2021 Nov 1-5; Mexico. New York: IEEE; 2021. p. 7332-7335.
[DOI] -
95. Nkurikiyeyezu K, Yokokubo A, Lopez G. Effect of person-specific biometrics in improving generic stress predictive models. Sens Mater. 2020;32:703-722.
[DOI] -
96. Islam T, Washington P. Individualized stress mobile sensing using self-supervised pre-training. Appl Sci. 2023;13(21):12035.
[DOI] -
97. Aqajari SAH, Wang Z, Tazarv A, Labbaf S, Jafarlou S, Nguyen B, et al. Enhancing performance and user engagement in everyday stress monitoring: A context-aware active reinforcement learning approach. arXiv:2407.08215 [Preprint] 2024;
[DOI]
Copyright
© The Author(s) 2025. This is an Open Access article licensed under a Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, sharing, adaptation, distribution and reproduction in any medium or format, for any purpose, even commercially, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Publisher’s Note
Science Exploration remains a neutral stance on jurisdictional claims in published maps
and institutional affiliations. The views expressed in this article are solely those of
the author(s) and do not reflect the opinions of the Editors or the publisher.
Share And Cite



Science Exploration Style
Dongre P, Behravan M, Gračanin D. Empathic extended reality in the era of generative AI. Empath Comput. 2025;1:202509. https://doi.org/10.70401/ec.2025.0009
Tips
Copy completed.
Submit a Manuscript
Author Instructions
Cite this Article
Article Metrics
0
View
0
Download
Article Updates
